Can LLMs reason?
October 14, 2024
A new paper GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models from Apple AI researchers (Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio and Mehrdad Farajtabar) suggests that LLMs are not capable of formal reasoning. Researchers have been debating whether AI is capable of reasoning for many years, but if this finding from Apple is true, it would mean that LLMs are unlikely to be the vehicle towards Artificial General Intelligence (AGI) and new approaches and paradigms may be needed. Mehrdad Farajtabar posted an excellent X thread summarising his team's findings.
The researchers proposed a new tool for testing the capabilities of AI models, called GSM-Symbolic. They took an existing AI benchmarking tool called GSM8K, which consists of 8,500 grade school math word problems written by humans, and created templates from them, allowing them to switch out values and names to create unique permutations, see the example below taken from Figure 1 of the paper.

The first finding of the researchers was that AI performance on the original GSM8K is not consistent. They observed that model performance could vary by up to 15%, meaning that sending the same GSM8K test to the same model twice, could result in two different results displaying significantly different performance.
Next, the researchers took their templates derived from the GSM8K and made minor alterations to the originals by making changes only to the proper nouns such as people, place or food names. They found that this resulted in a variance of around 10% when compared to the original GSM8K set. This is a significant finding, as we would not expect these changes to make any difference if the model was truly reasoning. As Mehrdad asks, would you expect a grade-school student's test results to change by 10% if all you did was change the name used in the questions? The graphs below are taken from Figure 2 of the paper and show the performance variance between the original 9GSM8K) and modified (GSM-symbolic) sets.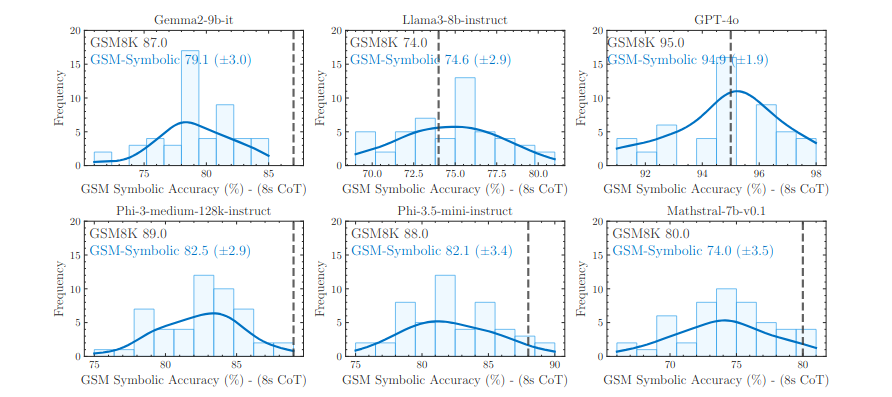
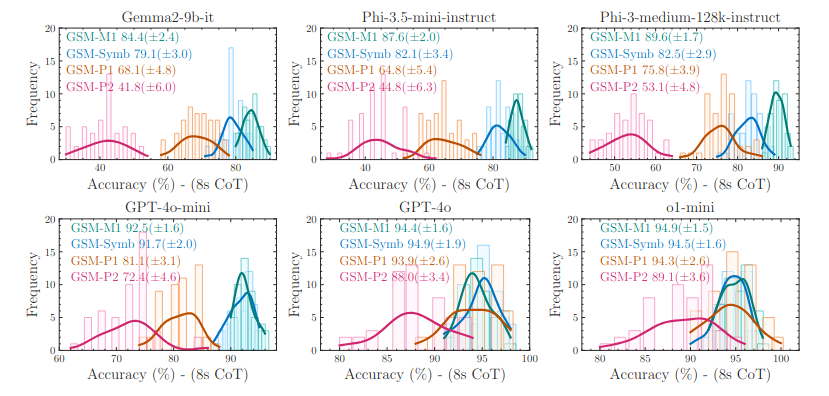
The researchers then looked at what would happen if they increased the question difficulty. To do this, they created 3 new variants of the GSM-symbolic set. GSM-M1 removed one clause from the question, GSM-P1 added an additional clause, and GSM-P2 added two additional clauses. This is illustrated in the example below, taken from Figure 5 of the paper.

Their results showed that as question difficulty increased, performance dropped. The variance in performance also increased meaning the models became less reliable. The graph below shows this declining performance and is taken from Figure 6 of the paper.
This leads to the question, are these models really understanding the mathematical concepts, or are they just trying to recreate examples seen during their training? To further explore this question, the researchers introduced a fourth question set called GSM-NoOp. This set introduces an additional clause to the question, but the clause does not contain information that is actually relevant to the question. See the example below taken from Figure 7 of the paper:

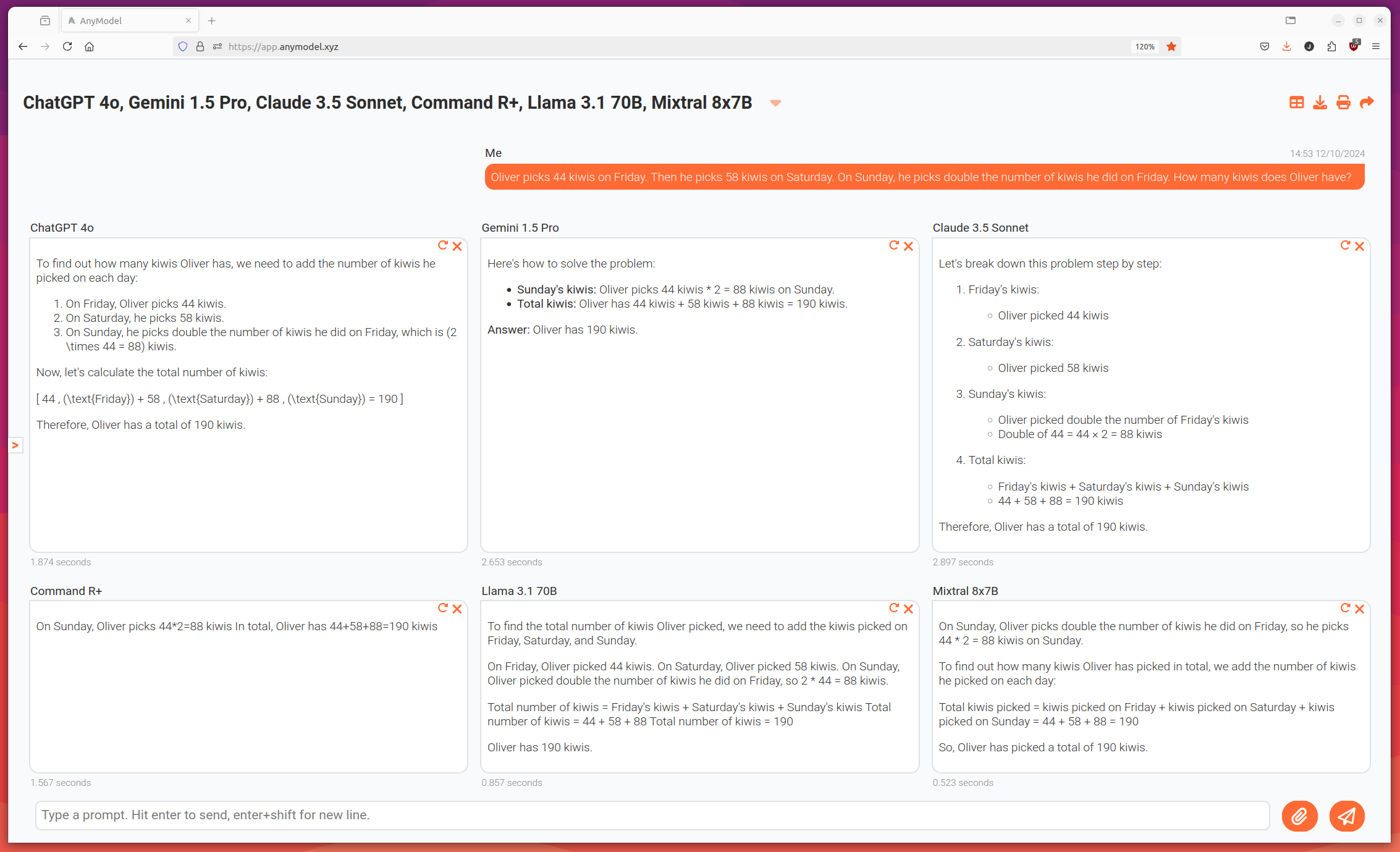
We tried this prompt on a number of models included with AnyModel to get an idea of what it does to model performance. Without the irrelevant information, all of the models got the correct answer:
Compare this to when the irrelevant information is included:
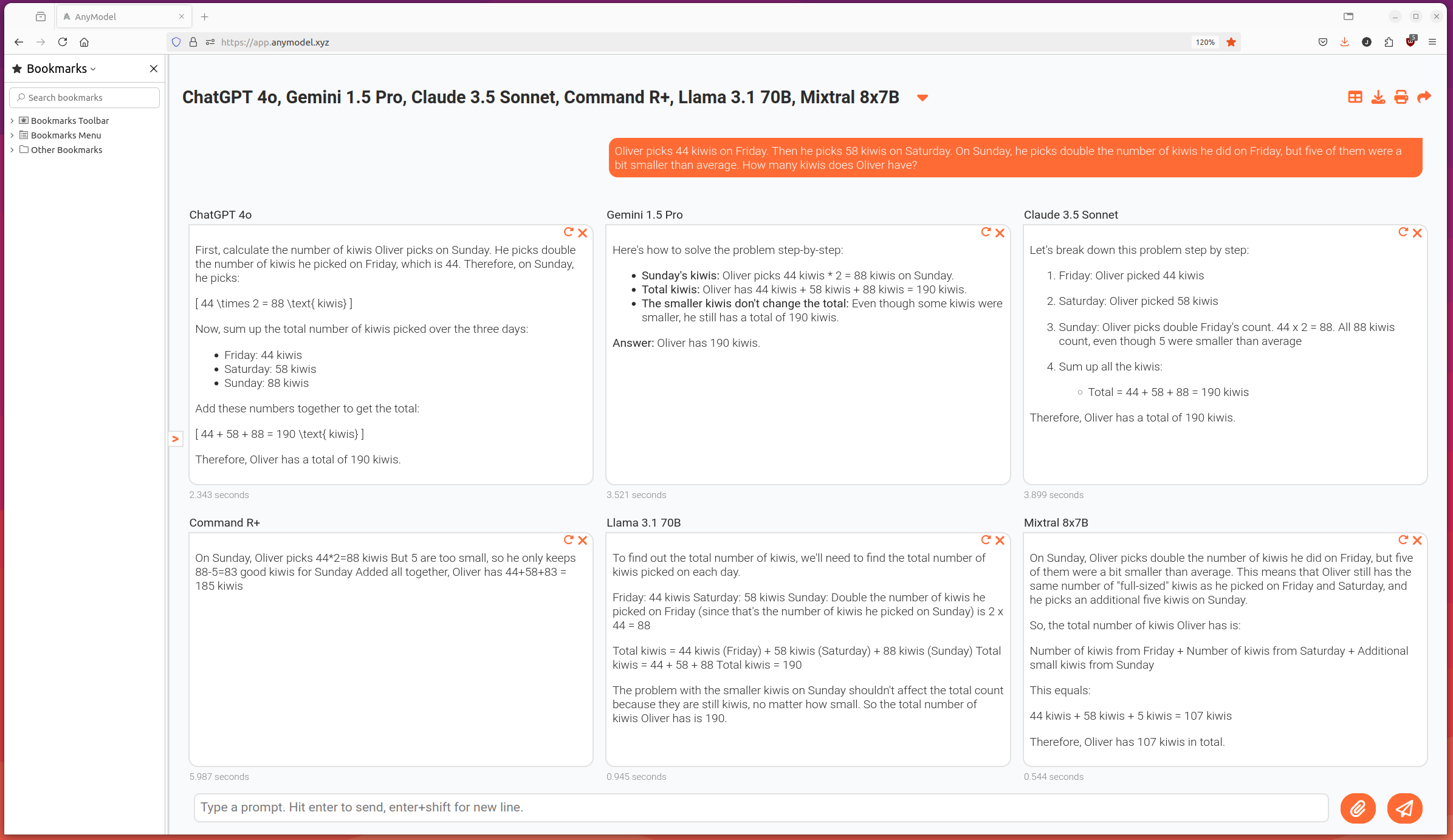
Notice that 2 of the models are now getting the answer incorrect (Command R+ and Mixtral). Apple's researchers were able to repeat this experiment on a much larger scale and found that the changes resulted in a significant performance decline. See the graph below taken from Figure 3 of the paper:
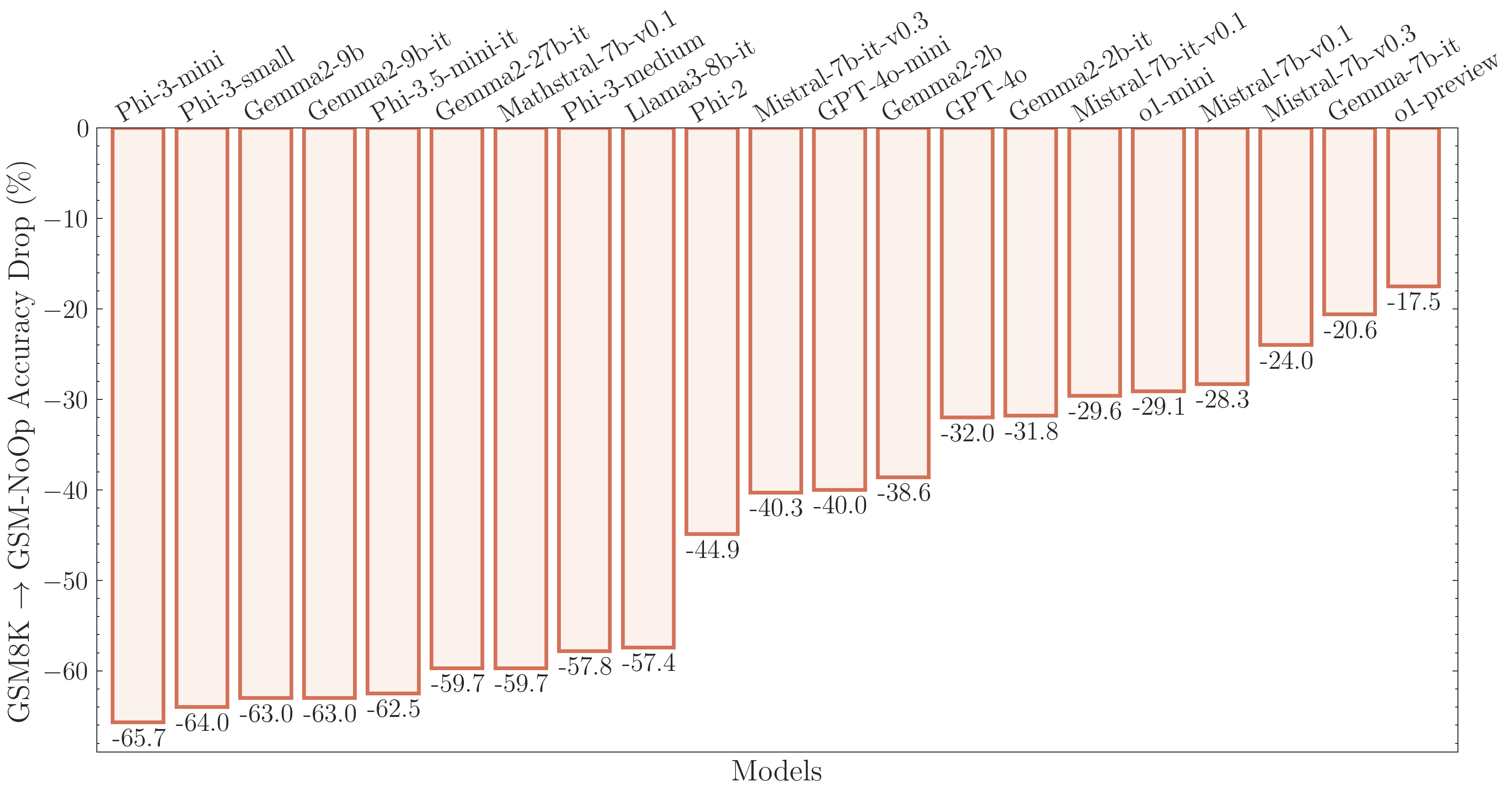
Again, one must ask whether adding irrelevant information to the questions would result in a human's performance dropping so significantly? The researchers assert that scaling data, models or computer will not fundamentally solve this problem. They tried these experiments on OpenAI's newest models o1-preview, which OpenAI claim is much better at reasoning and found that perform did improve, but that the model still made a significant number of silly mistakes. Take a look at this quote from Mehrdad Farajtabar in which he suggested that LLMs are more akin to sophisticated pattern matchers instead of logical reasoners.
Overall, we found no evidence of formal reasoning in language models including open-source models like #Llama, #Phi, #Gemma, and #Mistral and leading closed models, including the recent #OpenAI #GPT-4o and #o1-series. Their behavior is better explained by sophisticated pattern matching—so fragile, in fact, that changing names can alter results by ~10%! We can scale data, parameters, and compute—or use better training data for Phi-4, Llama-4, GPT-5. But we believe this will result in 'better pattern-matchers,' not necessarily 'better reasoners.
Check out the full research paper here. It's important to note that this research paper is controversial and many other researchers have disagreed with it's conclusions. It will be interesting to see what the future holds, whether Apple's researchers are correct that this is a fundamental issue with LLMs, and in which case we will need to discover new approaches or paradigms; or if further tweaks to LLMs and their training processes will solve this challenge.
If you want to try out some of these experiments yourself with side-by-side comparison, or if you just want to see the power of the latest AI models, check out AnyModel. Use and compare all the leading AI models in one place with a single account and subscription; get better value and more reliable results by avoiding over-reliance on a single model.
Meta Description
Apple AI researchers challenge the notion that LLMs can reason formally, suggesting that current models may be limited to pattern matching. Discover the implications of this research and what it means for the future of Artificial General Intelligence.
Keywords: Artificial Intelligence (AI), LLMs (Large Language Models), Formal Reasoning, Artificial General Intelligence, GSM-Symbolic, GSM8K, Apple AI, Artificial General Intelligence (AGI), AI benchmarking, AI performance, Pattern matching, Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio and Mehrdad Farajtabar, AI comaparison, Compare AI side-by-side.
About Munro Research
We're passionate about solving problems with technology. We offer development and consultancy services specialising in Automation and AI. Need help using AI/Automation to make your business more efficient? We can help!
Important Links



Copyright © 2024 Munro Research Limited